自定义组件专题

Callback 处理
回调概念
LangChain提供了一个回调系统,允许您连接到LLM应用程序的各个阶段。这对于日志记录、监控、流式处理和其他任务非常有用。 您可以通过使用API中的<font style="color:rgb(28, 30, 33);">callbacks</font>参数订阅这些事件。这个参数是处理程序对象的列表,这些处理程序对象应该实现下面更详细描述的一个或多个方法。
回调事件(Callback Events)
| Event | Event Trigger | Associated Method |
|---|---|---|
| Chat model start | When a chat model starts | on_chat_model_start |
| LLM start | When a llm starts | on_llm_start |
| LLM new token | When an llm OR chat model emits a new token | on_llm_new_token |
| LLM ends | When an llm OR chat model ends | on_llm_end |
| LLM errors | When an llm OR chat model errors | on_llm_error |
| Chain start | When a chain starts running | on_chain_start |
| Chain end | When a chain ends | on_chain_end |
| Chain error | When a chain errors | on_chain_error |
| Tool start | When a tool starts running | on_tool_start |
| Tool end | When a tool ends | on_tool_end |
| Tool error | When a tool errors | on_tool_error |
| Agent action | When an agent takes an action | on_agent_action |
| Agent finish | When an agent ends | on_agent_finish |
| Retriever start | When a retriever starts | on_retriever_start |
| Retriever end | When a retriever ends | on_retriever_end |
| Retriever error | When a retriever errors | on_retriever_error |
| Text | When arbitrary text is run | on_text |
| Retry | When a retry event is run | on_retry |
回调处理程序
<font style="color:rgb(28, 30, 33);">CallbackHandlers</font>是实现了CallbackHandler接口的对象,该接口对应于可以订阅的每个事件都有一个方法。 当事件触发时,<font style="color:rgb(28, 30, 33);">CallbackManager</font>将在每个处理程序上调用适当的方法。
#示例:callback_run.py
class BaseCallbackHandler:
"""可以用来处理langchain回调的基本回调处理程序。"""
def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> Any:
"""LLM开始运行时运行。"""
def on_chat_model_start(
self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], **kwargs: Any
) -> Any:
"""聊天模型开始运行时运行。"""
# 其他方法省略...传递回调函数
<font style="color:rgb(28, 30, 33);">callbacks</font> 属性在 API 的大多数对象(模型、工具、代理等)中都可用,在两个不同的位置上:
- 构造函数回调:在构造函数中定义,例如
<font style="color:#080808;background-color:#ffffff;">ChatOpenAI</font><font style="color:rgb(28, 30, 33);">(callbacks=[handler], tags=['a-tag'])</font>。在这种情况下,回调函数将用于该对象上的所有调用,并且仅限于该对象。 例如,如果你使用构造函数回调初始化了一个聊天模型,然后在链式调用中使用它,那么回调函数只会在对该模型的调用中被调用。 - 请求回调:传递给用于发出请求的
<font style="color:rgb(28, 30, 33);">invoke</font>方法。在这种情况下,回调函数仅用于该特定请求,以及它包含的所有子请求(例如,调用触发对模型的调用的序列的调用,该模型使用在<font style="color:rgb(28, 30, 33);">invoke()</font>方法中传递的相同处理程序)。 在<font style="color:rgb(28, 30, 33);">invoke()</font>方法中,通过<font style="color:rgb(28, 30, 33);">config</font>参数传递回调函数。
在运行时传递回调函数
许多情况下,当运行对象时,传递处理程序而不是回调函数会更有优势。当我们在执行运行时使用 <font style="color:rgb(28, 30, 33);">callbacks</font> 关键字参数传递 CallbackHandlers 时,这些回调函数将由执行中涉及的所有嵌套对象发出。例如,当通过一个处理程序传递给一个代理时,它将用于与代理相关的所有回调以及代理执行中涉及的所有对象,即工具和LLM。
这样可以避免我们手动将处理程序附加到每个单独的嵌套对象上。以下是一个示例:
#示例:callback_run.py
from typing import Any, Dict, List
from langchain_core.callbacks import BaseCallbackHandler
from langchain_core.messages import BaseMessage
from langchain_core.outputs import LLMResult
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
class LoggingHandler(BaseCallbackHandler):
def on_chat_model_start(
self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], **kwargs
) -> None:
print("Chat model started")
def on_llm_end(self, response: LLMResult, **kwargs) -> None:
print(f"Chat model ended, response: {response}")
def on_chain_start(
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs
) -> None:
print(f"Chain {serialized.get('name')} started")
def on_chain_end(self, outputs: Dict[str, Any], **kwargs) -> None:
print(f"Chain ended, outputs: {outputs}")
callbacks = [LoggingHandler()]
llm = ChatOpenAI(model="gpt-4")
prompt = ChatPromptTemplate.from_template("What is 1 + {number}?")
chain = prompt | llm
chain.invoke({"number": "2"}, config={"callbacks": callbacks})
Chain RunnableSequence started
Chain ChatPromptTemplate started
Chain ended, outputs: messages=[HumanMessage(content='What is 1 + 2?')]
Chat model started
Chat model ended, response: generations=[[ChatGeneration(text='3', generation_info={'finish_reason': 'stop', 'logprobs': None}, message=AIMessage(content='3', response_metadata={'token_usage': {'completion_tokens': 1, 'prompt_tokens': 15, 'total_tokens': 16}, 'model_name': 'gpt-4', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-ef28eacd-3f1c-4d6e-80da-63453a207efe-0'))]] llm_output={'token_usage': {'completion_tokens': 1, 'prompt_tokens': 15, 'total_tokens': 16}, 'model_name': 'gpt-4', 'system_fingerprint': None} run=None
Chain ended, outputs: content='3' response_metadata={'token_usage': {'completion_tokens': 1, 'prompt_tokens': 15, 'total_tokens': 16}, 'model_name': 'gpt-4', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run-ef28eacd-3f1c-4d6e-80da-63453a207efe-0'
自定义 callback handlers自定义 Chat model
LangChain具有一些内置的回调处理程序,但通常您会希望创建具有自定义逻辑的自定义处理程序。
要创建自定义回调处理程序,我们需要确定我们希望处理的event(s),以及在触发事件时我们希望回调处理程序执行的操作。然后,我们只需将回调处理程序附加到对象上,例如通过构造函数或运行时。
在下面的示例中,我们将使用自定义处理程序实现流式处理。
在我们的自定义回调处理程序<font style="color:rgb(28, 30, 33);">MyCustomHandler</font>中,我们实现了<font style="color:rgb(28, 30, 33);">on_llm_new_token</font>处理程序,以打印我们刚收到的令牌。然后,我们将自定义处理程序作为构造函数回调附加到模型对象上。
#示例:callback_process.py
from langchain_openai import ChatOpenAI
from langchain_core.callbacks import BaseCallbackHandler
from langchain_core.prompts import ChatPromptTemplate
class MyCustomHandler(BaseCallbackHandler):
def on_llm_new_token(self, token: str, **kwargs) -> None:
print(f"My custom handler, token: {token}")
prompt = ChatPromptTemplate.from_messages(["给我讲个关于{animal}的笑话,限制20个字"])
# 为启用流式处理,我们在ChatModel构造函数中传入`streaming=True`
# 另外,我们将自定义处理程序作为回调参数的列表传入
model = ChatOpenAI(
model="gpt-4", streaming=True, callbacks=[MyCustomHandler()]
)
chain = prompt | model
response = chain.invoke({"animal": "猫"})
print(response.content)My custom handler, token:
My custom handler, token: 猫
My custom handler, token: 对
My custom handler, token: 主
My custom handler, token: 人
My custom handler, token: 说
My custom handler, token: :"
My custom handler, token: 你
My custom handler, token: 知
My custom handler, token: 道
My custom handler, token: 我
My custom handler, token: 为
My custom handler, token: 什
My custom handler, token: 么
My custom handler, token: 不
My custom handler, token: 笑
My custom handler, token: 吗
My custom handler, token: ?
My custom handler, token: "
My custom handler, token: 主
My custom handler, token: 人
My custom handler, token: 摇
My custom handler, token: 头
My custom handler, token: ,
My custom handler, token: 猫
My custom handler, token: 说
My custom handler, token: :"
My custom handler, token: 因
My custom handler, token: 为
My custom handler, token: 我
My custom handler, token: 是
My custom handler, token: '
My custom handler, token: 喵
My custom handler, token: '
My custom handler, token: 星
My custom handler, token: 人
My custom handler, token: ,
My custom handler, token: 不
My custom handler, token: 是
My custom handler, token: 笑
My custom handler, token: 星
My custom handler, token: 人
My custom handler, token: 。
My custom handler, token: "
My custom handler, token:
猫对主人说:"你知道我为什么不笑吗?" 主人摇头,猫说:"因为我是'喵'星人,不是笑星人。"可以查看此参考页面以获取您可以处理的事件列表。请注意,<font style="color:rgb(28, 30, 33);">handle_chain_*</font>事件适用于大多数LCEL可运行对象。
自定义 RAG: Retriever, document loader
如何创建自定义Retriever(检索器)
概述
许多LLM应用程序涉及使用<font style="color:rgb(28, 30, 33);">Retriever</font>从外部数据源检索信息。 检索器负责检索与给定用户<font style="color:rgb(28, 30, 33);">query</font>相关的<font style="color:rgb(28, 30, 33);">Documents</font>列表。 检索到的文档通常被格式化为提示,然后输入LLM,使LLM能够使用其中的信息生成适当的响应(例如,基于知识库回答用户问题)。
接口
要创建自己的检索器,您需要扩展<font style="color:rgb(28, 30, 33);">BaseRetriever</font>类并实现以下方法:
| 方法 | 描述 | 必需/可选 |
|---|---|---|
| _get_relevant_documents | 获取与查询相关的文档。 | 必需 |
| _aget_relevant_documents | 实现以提供异步本机支持。 | 可选 |
<font style="color:rgb(28, 30, 33);">_get_relevant_documents</font>中的逻辑可以涉及对数据库或使用请求对网络进行任意调用。 通过从<font style="color:rgb(28, 30, 33);">BaseRetriever</font>继承,您的检索器将自动成为LangChain Runnable,并将获得标准的<font style="color:rgb(28, 30, 33);">Runnable</font>功能,您可以使用<font style="color:rgb(28, 30, 33);">RunnableLambda</font>或<font style="color:rgb(28, 30, 33);">RunnableGenerator</font>来实现检索器。 将检索器实现为<font style="color:rgb(28, 30, 33);">BaseRetriever</font>与将其实现为<font style="color:rgb(28, 30, 33);">RunnableLambda</font>(自定义runnable function)相比的主要优点是,<font style="color:rgb(28, 30, 33);">BaseRetriever</font>是一个众所周知的LangChain实体,因此一些监控工具可能会为检索器实现专门的行为。另一个区别是,在某些API中,<font style="color:rgb(28, 30, 33);">BaseRetriever</font>与<font style="color:rgb(28, 30, 33);">RunnableLambda</font>的行为略有不同;例如,在<font style="color:rgb(28, 30, 33);">astream_events</font> API中,<font style="color:rgb(28, 30, 33);">start</font>事件将是<font style="color:rgb(28, 30, 33);">on_retriever_start</font>,而不是<font style="color:rgb(28, 30, 33);">on_chain_start</font>。 :::
示例
让我们实现一个动物检索器,它返回所有文档中包含用户查询文本的文档。
#示例:retriever_animal.py
from typing import List
from langchain_core.callbacks import CallbackManagerForRetrieverRun, AsyncCallbackManagerForRetrieverRun
from langchain_core.documents import Document
from langchain_core.retrievers import BaseRetriever
import asyncio
class AnimalRetriever(BaseRetriever):
"""包含用户查询的前k个文档的动物检索器。k从0开始
该检索器实现了同步方法`_get_relevant_documents`。
如果检索器涉及文件访问或网络访问,它可以受益于`_aget_relevant_documents`的本机异步实现。
与可运行对象一样,提供了默认的异步实现,该实现委托给在另一个线程上运行的同步实现。
"""
documents: List[Document]
"""要检索的文档列表。"""
k: int
"""要返回的前k个结果的数量"""
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
"""检索器的同步实现。"""
matching_documents = []
for document in self.documents:
if len(matching_documents) >= self.k:
break
if query.lower() in document.page_content.lower():
matching_documents.append(document)
return matching_documents
async def _aget_relevant_documents(
self, query: str, *, run_manager: AsyncCallbackManagerForRetrieverRun
) -> List[Document]:
"""异步获取与查询相关的文档。
Args:
query: 要查找相关文档的字符串
run_manager: 要使用的回调处理程序
Returns:
相关文档列表
"""
matching_documents = []
for document in self.documents:
if len(matching_documents) >= self.k:
break
if query.lower() in document.page_content.lower():
matching_documents.append(document)
return matching_documents测试
documents = [
Document(
page_content="狗是很好的伴侣,以其忠诚和友好著称。",
metadata={"type": "狗", "trait": "忠诚"},
),
Document(
page_content="猫是独立的宠物,通常喜欢自己的空间。",
metadata={"type": "猫", "trait": "独立"},
),
Document(
page_content="金鱼是初学者的热门宠物,护理相对简单。",
metadata={"type": "鱼", "trait": "低维护"},
),
Document(
page_content="鹦鹉是聪明的鸟类,能够模仿人类的语言。",
metadata={"type": "鸟", "trait": "聪明"},
),
Document(
page_content="兔子是社交动物,需要足够的空间跳跃。",
metadata={"type": "兔子", "trait": "社交"},
),
]
retriever = ToyRetriever(documents=documents, k=1)retriever.invoke("宠物")[Document(metadata={'type': '猫', 'trait': '独立'}, page_content='猫是独立的宠物,通常喜欢自己的空间。'), Document(metadata={'type': '鱼', 'trait': '低维护'}, page_content='金鱼是初学者的热门宠物,护理相对简单。')]这是一个可运行的示例,因此它将受益于标准的 Runnable 接口!🤩
await retriever.ainvoke("狗")[Document(metadata={'type': '狗', 'trait': '忠诚'}, page_content='狗是很好的伴侣,以其忠诚和友好著称。')]retriever.batch(["猫", "兔子"])[Document(metadata={'type': '狗', 'trait': '忠诚'}, page_content='狗是很好的伴侣,以其忠诚和友好著称。')]async for event in retriever.astream_events("猫", version="v1"):
print(event){'event': 'on_retriever_start', 'run_id': 'c0101364-5ef3-4756-9ece-83845892cf59', 'name': 'AnimalRetriever', 'tags': [], 'metadata': {}, 'data': {'input': '猫'}, 'parent_ids': []}
{'event': 'on_retriever_stream', 'run_id': 'c0101364-5ef3-4756-9ece-83845892cf59', 'tags': [], 'metadata': {}, 'name': 'AnimalRetriever', 'data': {'chunk': [Document(metadata={'type': '猫', 'trait': '独立'}, page_content='猫是独立的宠物,通常喜欢自己的空间。')]}, 'parent_ids': []}
{'event': 'on_retriever_end', 'name': 'AnimalRetriever', 'run_id': 'c0101364-5ef3-4756-9ece-83845892cf59', 'tags': [], 'metadata': {}, 'data': {'output': [Document(metadata={'type': '猫', 'trait': '独立'}, page_content='猫是独立的宠物,通常喜欢自己的空间。')]}, 'parent_ids': []}如何创建自定义Document loader(文档加载器)
概述
基于LLM的应用程序通常涉及从数据库或文件(如PDF)中提取数据,并将其转换为LLM可以利用的格式。在LangChain中,这通常涉及创建Document对象,该对象封装了提取的文本(<font style="color:rgb(28, 30, 33);">page_content</font>)以及元数据 - 包含有关文档的详细信息的字典,例如作者姓名或出版日期。 <font style="color:rgb(28, 30, 33);">Document</font>对象通常被格式化为提示,然后输入LLM,以便LLM可以使用<font style="color:rgb(28, 30, 33);">Document</font>中的信息生成所需的响应(例如,对文档进行摘要)。 <font style="color:rgb(28, 30, 33);">Documents</font>可以立即使用,也可以索引到向量存储中以供将来检索和使用。 文档加载的主要抽象为:
| 组件 | 描述 |
|---|---|
| Document | 包含 text 和 metadata 的内容 |
| BaseLoader | 用于将原始数据转换为 Documents |
| Blob | 二进制数据的表示,可以位于文件或内存中 |
| BaseBlobParser | 解析 Blob 以生成 Document 对象的逻辑 |
下面将演示如何编写自定义文档加载和文件解析逻辑;具体而言,我们将看到如何:
- 通过从
<font style="color:rgb(28, 30, 33);">BaseLoader</font>进行子类化来创建标准文档加载器。 - 使用
<font style="color:rgb(28, 30, 33);">BaseBlobParser</font>创建解析器,并将其与<font style="color:rgb(28, 30, 33);">Blob</font>和<font style="color:rgb(28, 30, 33);">BlobLoaders</font>结合使用。这在处理文件时非常有用。
标准文档加载器
可以通过从<font style="color:rgb(28, 30, 33);">BaseLoader</font>进行子类化来实现文档加载器,<font style="color:rgb(28, 30, 33);">BaseLoader</font>提供了用于加载文档的标准接口。
接口
| 方法名 | 说明 |
|---|---|
| lazy_load | 用于惰性逐个加载文档。用于生产代码。 |
| alazy_load | lazy_load的异步变体 |
| load | 用于急切将所有文档加载到内存中。用于交互式工作。 |
| aload | 用于急切将所有文档加载到内存中。用于交互式工作。在2024-04添加到LangChain。 |
<font style="color:rgb(28, 30, 33);">load</font>方法是一个方便的方法,仅用于交互式工作 - 它只是调用<font style="color:rgb(28, 30, 33);">list(self.lazy_load())</font>。<font style="color:rgb(28, 30, 33);">alazy_load</font>具有默认实现,将委托给<font style="color:rgb(28, 30, 33);">lazy_load</font>。如果您使用异步操作,建议覆盖默认实现并提供本机异步实现。 {.callout-important} 在实现文档加载器时,不要通过<font style="color:rgb(28, 30, 33);">lazy_load</font>或<font style="color:rgb(28, 30, 33);">alazy_load</font>方法传递参数。 所有配置都应通过初始化器(init)传递。这是LangChain的设计选择,以确保一旦实例化了文档加载器,它就具有加载文档所需的所有信息。
实现
让我们创建一个标准文档加载器的示例,该加载器从文件中加载数据,并从文件的每一行创建一个文档。
#示例:doc_loader_custom.py
from typing import AsyncIterator, Iterator
from langchain_core.document_loaders import BaseLoader
from langchain_core.documents import Document
class CustomDocumentLoader(BaseLoader):
"""一个从文件逐行读取的示例文档加载器。"""
def __init__(self, file_path: str) -> None:
"""使用文件路径初始化加载器。
Args:
file_path: 要加载的文件的路径。
"""
self.file_path = file_path
def lazy_load(self) -> Iterator[Document]: # <-- 不接受任何参数
"""逐行读取文件的惰性加载器。
当您实现惰性加载方法时,应使用生成器逐个生成文档。
"""
with open(self.file_path, encoding="utf-8") as f:
line_number = 0
for line in f:
yield Document(
page_content=line,
metadata={"line_number": line_number, "source": self.file_path},
)
line_number += 1
# alazy_load是可选的。
# 如果您省略了实现,将使用默认实现,该实现将委托给lazy_load!
async def alazy_load(
self,
) -> AsyncIterator[Document]: # <-- 不接受任何参数
"""逐行读取文件的异步惰性加载器。"""
# 需要aiofiles
# 使用`pip install aiofiles`安装
# https://github.com/Tinche/aiofiles
import aiofiles
async with aiofiles.open(self.file_path, encoding="utf-8") as f:
line_number = 0
async for line in f:
yield Document(
page_content=line,
metadata={"line_number": line_number, "source": self.file_path},
)
line_number += 1测试
为了测试文档加载器,我们需要一个包含一些优质内容的文件。
with open("./meow.txt", "w", encoding="utf-8") as f:
quality_content = "喵喵🐱 \n 喵喵🐱 \n 喵😻😻"
f.write(quality_content)
loader = CustomDocumentLoader("./meow.txt")## 测试延迟加载接口
for doc in loader.lazy_load():
print()
print(type(doc))
print(doc)<class 'langchain_core.documents.base.Document'>
page_content='喵喵🐱
' metadata={'line_number': 0, 'source': './meow.txt'}
<class 'langchain_core.documents.base.Document'>
page_content=' 喵喵🐱
' metadata={'line_number': 1, 'source': './meow.txt'}
<class 'langchain_core.documents.base.Document'>
page_content=' 喵😻😻' metadata={'line_number': 2, 'source': './meow.txt'}## 测试异步实现
async for doc in loader.alazy_load():
print()
print(type(doc))
print(doc)<class 'langchain_core.documents.base.Document'>
page_content='喵喵🐱
' metadata={'line_number': 0, 'source': './meow.txt'}
<class 'langchain_core.documents.base.Document'>
page_content=' 喵喵🐱
' metadata={'line_number': 1, 'source': './meow.txt'}
<class 'langchain_core.documents.base.Document'>
page_content=' 喵😻😻' metadata={'line_number': 2, 'source': './meow.txt'}::: {.callout-tip} <font style="color:rgb(28, 30, 33);">load()</font> 在诸如 Jupyter Notebook 之类的交互式环境中很有用。 在生产代码中避免使用它,因为急切加载假定所有内容都可以放入内存中,而这并不总是成立,特别是对于企业数据而言。 :::
loader.load()[Document(metadata={'line_number': 0, 'source': './meow.txt'}, page_content='喵喵🐱 \n'), Document(metadata={'line_number': 1, 'source': './meow.txt'}, page_content=' 喵喵🐱 \n'), Document(metadata={'line_number': 2, 'source': './meow.txt'}, page_content=' 喵😻😻')]文件处理
许多文档加载器涉及解析文件。这些加载器之间的区别通常在于文件的解析方式,而不是文件的加载方式。例如,您可以使用 <font style="color:rgb(28, 30, 33);">open</font> 来读取 PDF 或 markdown 文件的二进制内容,但您需要不同的解析逻辑来将该二进制数据转换为文本。 因此,将解析逻辑与加载逻辑分离可能会很有帮助,这样无论数据如何加载,都更容易重用给定的解析器。
BaseBlobParser
<font style="color:rgb(28, 30, 33);">BaseBlobParser</font> 是一个接口,接受一个 <font style="color:rgb(28, 30, 33);">blob</font> 并输出一个 <font style="color:rgb(28, 30, 33);">Document</font> 对象列表。<font style="color:rgb(28, 30, 33);">blob</font> 是一个表示数据的对象,可以存在于内存中或文件中。LangChain Python 具有受 Blob WebAPI 规范 启发的 <font style="color:rgb(28, 30, 33);">Blob</font> 原语。
#示例:doc_blob_parser.py
from langchain_core.document_loaders import BaseBlobParser, Blob
class MyParser(BaseBlobParser):
"""一个简单的解析器,每行创建一个文档。"""
def lazy_parse(self, blob: Blob) -> Iterator[Document]:
"""逐行将 blob 解析为文档。"""
line_number = 0
with blob.as_bytes_io() as f:
for line in f:
line_number += 1
yield Document(
page_content=line,
metadata={"line_number": line_number, "source": blob.source},
)blob = Blob.from_path("./meow.txt")
parser = MyParser()list(parser.lazy_parse(blob))[Document(page_content='喵喵🐱 \n', metadata={'line_number': 1, 'source': './meow.txt'}),
Document(page_content=' 喵喵🐱 \n', metadata={'line_number': 2, 'source': './meow.txt'}),
Document(page_content=' 喵😻😻', metadata={'line_number': 3, 'source': './meow.txt'})]使用 blob API 还允许直接从内存加载内容,而无需从文件中读取!
#示例:doc_blob_parser.py
blob = Blob(data=b"来自内存的一些数据\n喵")
list(parser.lazy_parse(blob))[Document(page_content='来自内存的一些数据\n', metadata={'line_number': 1, 'source': None}),
Document(page_content='喵', metadata={'line_number': 2, 'source': None})]Blob
让我们快速浏览一下 Blob API 的一些内容。
#示例:doc_blob_api.py
blob = Blob.from_path("./meow.txt", metadata={"foo": "bar"})blob.encoding'utf-8'blob.as_bytes()b'\xe5\x96\xb5\xe5\x96\xb5\xf0\x9f\x90\xb1 \r\n \xe5\x96\xb5\xe5\x96\xb5\xf0\x9f\x90\xb1 \r\n \xe5\x96\xb5\xf0\x9f\x98\xbb\xf0\x9f\x98\xbb'blob.as_string()喵喵🐱
喵喵🐱
喵😻😻blob.as_bytes_io()<contextlib._GeneratorContextManager object at 0x0000012E064CC2F0>Blob 元数据
blob.metadata{'foo': 'bar'}blob.source./meow.txtBlob 加载器
在解析器中封装了将二进制数据解析为文档所需的逻辑,blob 加载器 封装了从给定存储位置加载 blob 所需的逻辑。 目前,<font style="color:rgb(28, 30, 33);">LangChain</font> 仅支持 <font style="color:rgb(28, 30, 33);">FileSystemBlobLoader</font>。 您可以使用 <font style="color:rgb(28, 30, 33);">FileSystemBlobLoader</font> 加载 blob,然后使用解析器对其进行解析。
#示例:doc_blob_loader.py
from langchain_community.document_loaders.blob_loaders import FileSystemBlobLoader
blob_loader = FileSystemBlobLoader(path=".", glob="*.mdx", show_progress=True)parser = MyParser()
for blob in blob_loader.yield_blobs():
for doc in parser.lazy_parse(blob):
print(doc)
break100%|██████████| 8/8 [00:00<00:00, 8087.35it/s]page_content='# CSV
' metadata={'line_number': 1, 'source': '..\\resource\\csv.mdx'}
page_content='# File Directory
' metadata={'line_number': 1, 'source': '..\\resource\\file_directory.mdx'}
page_content='# HTML
' metadata={'line_number': 1, 'source': '..\\resource\\html.mdx'}
page_content='---
' metadata={'line_number': 1, 'source': '..\\resource\\index.mdx'}
page_content='# JSON
' metadata={'line_number': 1, 'source': '..\\resource\\json.mdx'}
page_content='# Markdown
' metadata={'line_number': 1, 'source': '..\\resource\\markdown.mdx'}
page_content='# Microsoft Office
' metadata={'line_number': 1, 'source': '..\\resource\\office_file.mdx'}
page_content='---
' metadata={'line_number': 1, 'source': '..\\resource\\pdf.mdx'}通用加载器
LangChain 拥有一个 <font style="color:rgb(28, 30, 33);">GenericLoader</font> 抽象,它将 <font style="color:rgb(28, 30, 33);">BlobLoader</font> 与 <font style="color:rgb(28, 30, 33);">BaseBlobParser</font> 结合在一起。 <font style="color:rgb(28, 30, 33);">GenericLoader</font> 旨在提供标准化的类方法,使现有的 <font style="color:rgb(28, 30, 33);">BlobLoader</font> 实现易于使用。目前,仅支持 <font style="color:rgb(28, 30, 33);">FileSystemBlobLoader</font>。
#示例:doc_blob_loader_generic.py
from langchain_community.document_loaders.generic import GenericLoader
loader = GenericLoader.from_filesystem(
path=".", glob="*.mdx", show_progress=True, parser=MyParser()
)
for idx, doc in enumerate(loader.lazy_load()):
if idx < 5:
print(doc)
print("... output truncated for demo purposes")100%|██████████| 8/8 [00:00<00:00, 78.69it/s]page_content='# CSV
' metadata={'line_number': 1, 'source': '..\\resource\\csv.mdx'}
page_content='# File Directory
' metadata={'line_number': 1, 'source': '..\\resource\\file_directory.mdx'}
page_content='# HTML
' metadata={'line_number': 1, 'source': '..\\resource\\html.mdx'}
page_content='---
' metadata={'line_number': 1, 'source': '..\\resource\\index.mdx'}
page_content='# JSON
' metadata={'line_number': 1, 'source': '..\\resource\\json.mdx'}
... output truncated for demo purposes自定义通用加载器
如果您喜欢创建类,您可以子类化并创建一个类来封装逻辑。 您可以从这个类中子类化以使用现有的加载器加载内容。
#示例:doc_blob_loader_generic_custom.py
from typing import Any
class MyCustomLoader(GenericLoader):
@staticmethod
def get_parser(**kwargs: Any) -> BaseBlobParser:
"""Override this method to associate a default parser with the class."""
return MyParser()loader = MyCustomLoader.from_filesystem(path=".", glob="*.mdx", show_progress=True)
for idx, doc in enumerate(loader.lazy_load()):
if idx < 5:
print(doc)
print("... output truncated for demo purposes")100%|██████████| 8/8 [00:00<00:00, 80.28it/s]page_content='# CSV
' metadata={'line_number': 1, 'source': '..\\resource\\csv.mdx'}
page_content='# File Directory
' metadata={'line_number': 1, 'source': '..\\resource\\file_directory.mdx'}
page_content='# HTML
' metadata={'line_number': 1, 'source': '..\\resource\\html.mdx'}
page_content='---
' metadata={'line_number': 1, 'source': '..\\resource\\index.mdx'}
page_content='# JSON
' metadata={'line_number': 1, 'source': '..\\resource\\json.mdx'}
... output truncated for demo purposes自定义对话历史状态管理
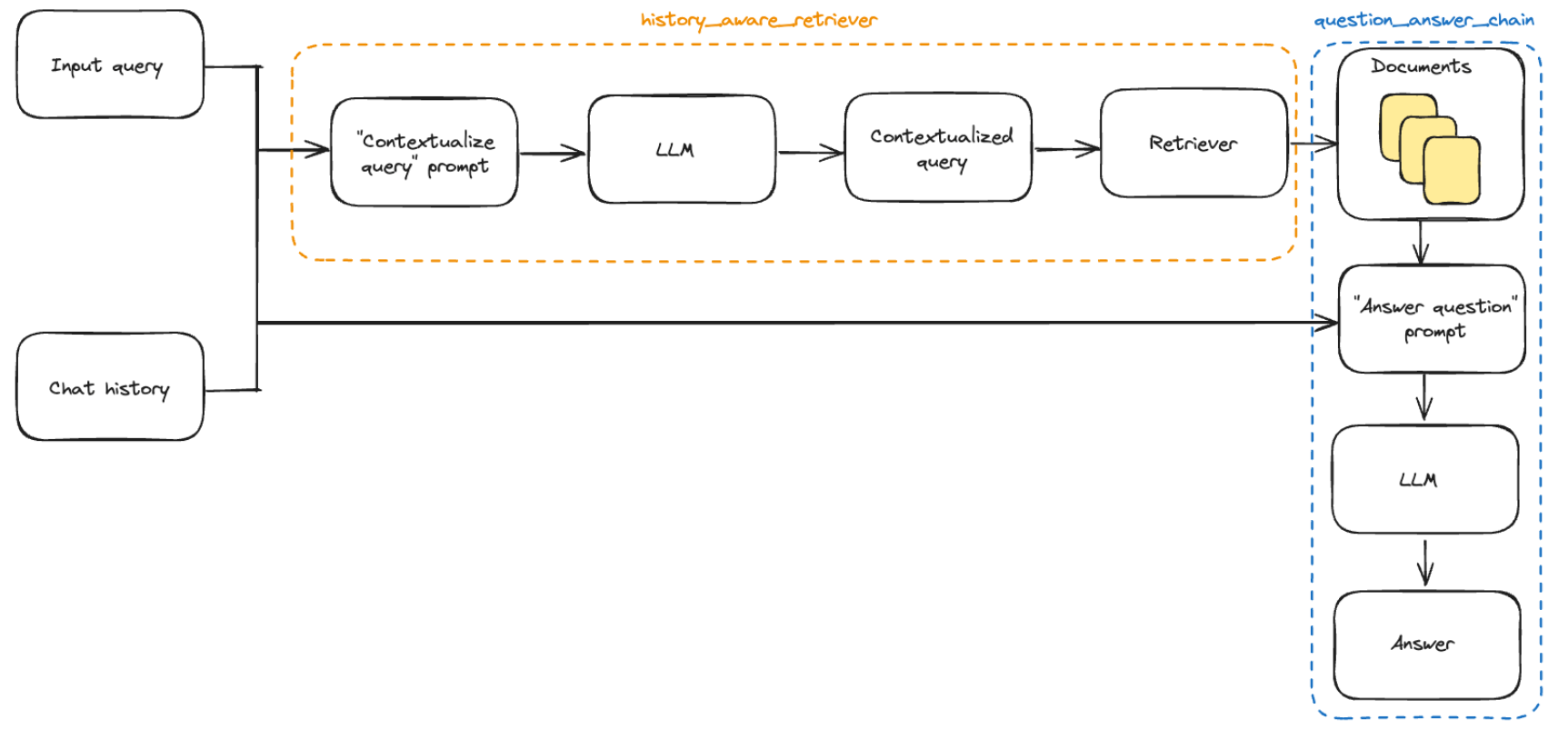
之前我们已经介绍了如何添加会话历史记录,但我们仍在手动更新对话历史并将其插入到每个输入中。在真正的问答应用程序中,我们希望有一种持久化对话历史的方式,并且有一种自动插入和更新它的方式。 为此,我们可以使用:
- BaseChatMessageHistory: 存储对话历史。
- RunnableWithMessageHistory: LCEL 链和
<font style="color:rgb(28, 30, 33);">BaseChatMessageHistory</font>的包装器,负责将对话历史注入输入并在每次调用后更新它。 要详细了解如何将这些类结合在一起创建有状态的对话链,请转到 如何添加消息历史(内存) LCEL 页面。 下面,我们实现了第二种选项的一个简单示例,其中对话历史存储在一个简单的字典中。<font style="color:rgb(28, 30, 33);">RunnableWithMessageHistory</font>的实例会为您管理对话历史。它们接受一个带有键(默认为<font style="color:rgb(28, 30, 33);">"session_id"</font>)的配置,该键指定要获取和预置到输入中的对话历史,并将输出附加到相同的对话历史。以下是一个示例:
#示例:custom_chat_session.py
# pip install --upgrade langchain langchain-community langchainhub langchain-chroma bs4
import bs4
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.messages import AIMessage, HumanMessage
from langchain.globals import set_debug
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_history_aware_retriever
from langchain.chains import create_retrieval_chain
# 打印调试日志
set_debug(False)
# 创建一个 WebBaseLoader 对象,用于从指定网址加载文档
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
# 加载文档
docs = loader.load()
# 创建一个 RecursiveCharacterTextSplitter 对象,用于将文档拆分成较小的文本块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
# 将文档拆分成文本块
splits = text_splitter.split_documents(docs)
# 创建一个 Chroma 对象,用于存储文本块的向量表示
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# 将向量存储转换为检索器
retriever = vectorstore.as_retriever()
# 定义系统提示词模板
system_prompt = (
"您是一个用于问答任务的助手。"
"使用以下检索到的上下文片段来回答问题。"
"如果您不知道答案,请说您不知道。"
"最多使用三句话,保持回答简洁。"
"\n\n"
"{context}"
)
# 创建一个 ChatPromptTemplate 对象,用于生成提示词
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
# 创建一个带有聊天历史记录的提示词模板
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
# 创建一个 ChatOpenAI 对象,表示聊天模型
llm = ChatOpenAI()
# 创建一个问答链
question_answer_chain = create_stuff_documents_chain(llm, prompt)
# 创建一个检索链,将检索器和问答链结合
rag_chain = create_retrieval_chain(retriever, question_answer_chain)
# 定义上下文化问题的系统提示词
contextualize_q_system_prompt = (
"给定聊天历史和最新的用户问题,"
"该问题可能引用聊天历史中的上下文,"
"重新构造一个可以在没有聊天历史的情况下理解的独立问题。"
"如果需要,不要回答问题,只需重新构造问题并返回。"
)
# 创建一个上下文化问题提示词模板
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
# 创建一个带有历史记录感知的检索器
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
# 创建一个带有聊天历史记录的问答链
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
# 创建一个带有历史记录感知的检索链
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
# 创建一个字典,用于存储聊天历史记录
store = {}
# 定义一个函数,用于获取指定会话的聊天历史记录
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
# 创建一个 RunnableWithMessageHistory 对象,用于管理有状态的聊天历史记录
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)# 调用有状态的检索链,获取回答
response = conversational_rag_chain.invoke(
{"input": "什么是任务分解?"},
config={
"configurable": {"session_id": "abc123"}
}, # 在 `store` 中构建一个键为 "abc123" 的键。
)["answer"]
print(response)任务分解是将复杂任务拆分成多个较小、简单的步骤的过程。通过任务分解,代理可以更好地理解任务的各个部分,并事先规划好执行顺序。这可以通过不同的方法实现,如使用提示或指令,或依靠人类输入。# 再次调用有状态的检索链,获取另一个回答
response = conversational_rag_chain.invoke(
{"input": "我刚刚问了什么?"},
config={"configurable": {"session_id": "abc123"}},
)["answer"]
print(response)任务分解是将复杂任务拆分成多个较小、简单的步骤的过程。通过任务分解,代理可以更好地理解任务的各个部分,并事先规划好执行顺序。这可以通过不同的方法实现,如使用提示或指令,或依靠人类输入。换一个session_id调用,会话不再共享
# 再次调用有状态的检索链,换一个session_id
response = conversational_rag_chain.invoke(
{"input": "我刚刚问了什么?"},
config={"configurable": {"session_id": "abc456"}},
)["answer"]
print(response)您最近询问了有关一个经典平台游戏的信息,其中主角是名叫Mario的管道工,游戏共有10个关卡,主角可以行走和跳跃,需要避开障碍物和敌人的攻击。对话历史可以在 <font style="color:rgb(28, 30, 33);">store</font> 字典中检查:
# 打印存储在会话 "abc123" 中的所有消息
for message in store["abc123"].messages:
if isinstance(message, AIMessage):
prefix = "AI"
else:
prefix = "User"
print(f"{prefix}: {message.content}\n")User: 什么是任务分解?
AI: 任务分解是将复杂任务拆分成多个较小、简单的步骤的过程。通过任务分解,代理可以更好地理解任务的各个部分,并事先规划好执行顺序。这可以通过不同的方法实现,如使用提示或指令,或依靠人类输入。
User: 我刚刚问了什么?
AI: 您刚刚问了关于任务分解的问题。任务分解是将复杂任务拆分成多个较小、简单的步骤的过程。这有助于代理更好地理解任务并规划执行顺序。